|
by Ziwen Zhou '23 Edited by Ishaani Khatri '21 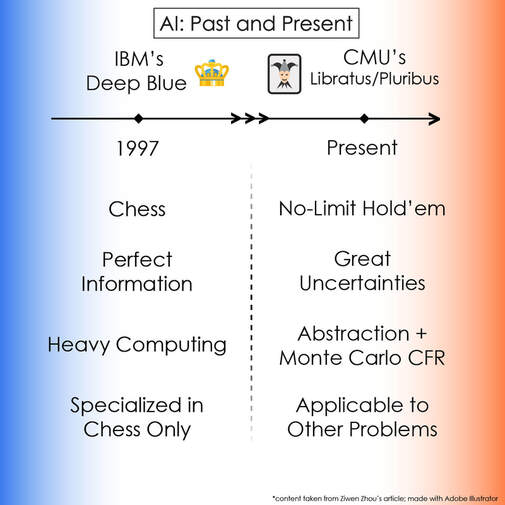 The general public has long had a complex relationship with artificial intelligence, or AI. Through iconic cinematic franchises such as The Matrix and The Terminator, we’ve recoiled in fear at the fantastically malevolent machines in all their visceral detail. We’ve marveled at how far robots have come to imitating human mannerisms and patterns. And in more modern times, we’ve worried about the effect automation will have on future employment prospects. But what if the continued evolution and advancement of AI takes a completely divergent path? Recent breakthroughs in deep learning and neural networking have led to a monumental redefinition of the conventional limits and possibilities of AI, particularly with the unprecedented and wholly unexpected successes of Carnegie Mellon’s poker-playing bots Libratus and Pluribus. As long as computers have existed, their abilities have been measured against those of humans— often in direct competition with the world’s leading minds in their respective realms. After decades of futility, AI finally broke through in 1997 as IBM’s Deep Blue program vanquished the reigning World Chess Champion Garry Kasparov to widespread public recognition and fanfare. Seeing as this landmark achievement occurred over two decades ago, why has Libratus’ poker preeminence suddenly been hailed as the dawn of a new age? What distinguishes poker and chess as games of strategy? While to a human chess and poker may be equally intuitive to comprehend, from a game theory and programming perspective the two are extremely different. Both games are zero-sum, signifying that whatever one player gains comes at others' expense. Chess, however, is a relatively simple perfect information game contested by two combatants; that is, both players clearly know the position on the board. Even though it is infeasible for any AI to calculate any given chess position to its definitive conclusion (exact ending position with a win for either player or a draw) with optimal play, with some sophistication in heuristic evaluation mastering chess merely becomes a computational problem. For example, Deep Blue triumphed over Kasparov by calculating over 200 million positions a second; nowadays with computing power increasing exponentially every year under the auspices of Moore’s Law, chess supercomputers can calculate far more [1]. On the other hand, more informationally complex games like Go, in which concrete calculation of divergent variations and objectively evaluating who is favored to triumph in any given position are astoundingly difficult, and games of incomplete information like poker were long predicted to remain a bastion of human dominance for the foreseeable future [1]. Instead, AI has emerged triumphant by exchanging pure computing ability for neural networking and deep learning. Google’s AlphaZero, the AI unanimously believed to be both the strongest chess and Go player in the world, calculates a mere 80,000 positions a second (orders of magnitude fewer than Deep Blue from over two decades ago) [2]. Poker, and especially the six-player no-limit Texas Hold’em variety are particularly challenging for AI as there is hardly any computing element involved. Even AlphaZero was reliant on computing power to a degree, but not even the strongest supercomputer could come anywhere close to brute forcing a solution to poker. As the only information known for certain to any player are the two cards they hold, many uncertainties need to be processed and resolved: the chance probabilities of unrevealed community cards, the possibility of deceit from opponents (in the form of bluffing), the evaluation of bet sizing by opponents, and finally the difficulty in optimizing your own betting strategy [3]. As a result, it’s all the more surprising that Libratus crushed the world’s best in heads-up no-limit hold’em, and Pluribus scored a resounding victory against five of the world’s top multiplayer no-limit hold’em competitors [3,4]. Libratus and Pluribus resolved these difficulties with two innovative solutions: abstraction and Monte Carlo counterfactual regret minimization (CFR). Through abstraction, defined by Carnegie Mellon researchers as “combining similar decision points together,” of betting and hand combinations, Pluribus could simplify the game of poker greatly [4]. By grouping different bet sizes together and classifying poker hands of similar strength as identical, Pluribus could more readily judge opponents’ betting strategies, determine its own bet sizing, and predict its own relative hand strength. But it is the use of Monte Carlo CFR that was particularly ingenius. CFR refers to a training system where an AI starts by playing itself with an arbitrarily random strategy but gradually improves by figuring out how to beat previous iterations of itself. As a result, over thousands upon thousands of games against themselves, Libratus and Pluribus were able to improve their quality of play as they learned from the mistakes previous iterations had committed (Monte Carlo refers to the random sampling of specific instances of play: both AI refined their strategy by analyzing and discovering improvements upon randomly chosen hands) [3,4]. Most importantly though, Libratus and Pluribus were not constructed solely for the purpose of poker [3,4]. Through their abstraction ability and their CFR training algorithm, both are adept at analyzing complex problems with incomplete information and uncooperative opponents, which mirror many real-world situations. Case in point, earlier this year the Pentagon officially signed a multimillion dollar contract to utilize Libratus’ capabilities to improve its war game training programs [5]. Who knows what other applications Libratus or Pluribus can be converted to perform? Some AI experts think they can be used to optimize cybersecurity and business negotiations to a point that defy even the limits of our imagination. Regardless, Libratus and Pluribus have drastically redefined the future of AI. Works Cited:
[1] Koch C. How the Computer Beat the Go Master [Internet]. Scientific American. 2016 [cited 2019Oct21]. Available from: https://www.scientificamerican.com/article/how-the-computer-beat-the-go-master/ [2] David, Hubert, Thomas, Julian, Ioannis, Lai, et al. Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm [Internet]. arXiv.org. 2017 [cited 2019Oct21]. Available from: https://arxiv.org/abs/1712.01815 [3] Brown N, Sandholm T. Superhuman AI for heads-up no-limit poker: Libratus beats top professionals [Internet]. Science. American Association for the Advancement of Science; 2018 [cited 2019Oct21]. Available from: https://science.sciencemag.org/content/359/6374/418 [4] Brown N, Sandholm T. Superhuman AI for multiplayer poker [Internet]. Science. American Association for the Advancement of Science; 2019 [cited 2019Oct21]. Available from: https://science.sciencemag.org/content/365/6456/885 [5] Menear H. Pentagon spends $10mn on poker playing AI Libratus [Internet]. USA. 2019 [cited 2019Oct21]. Available from: https://www.businesschief.com/technology/7762/Pentagon-spends-10mn-on-poker-playing-AI-Libratus
0 Comments
Leave a Reply. |
