|
by Dylan Sam, '21
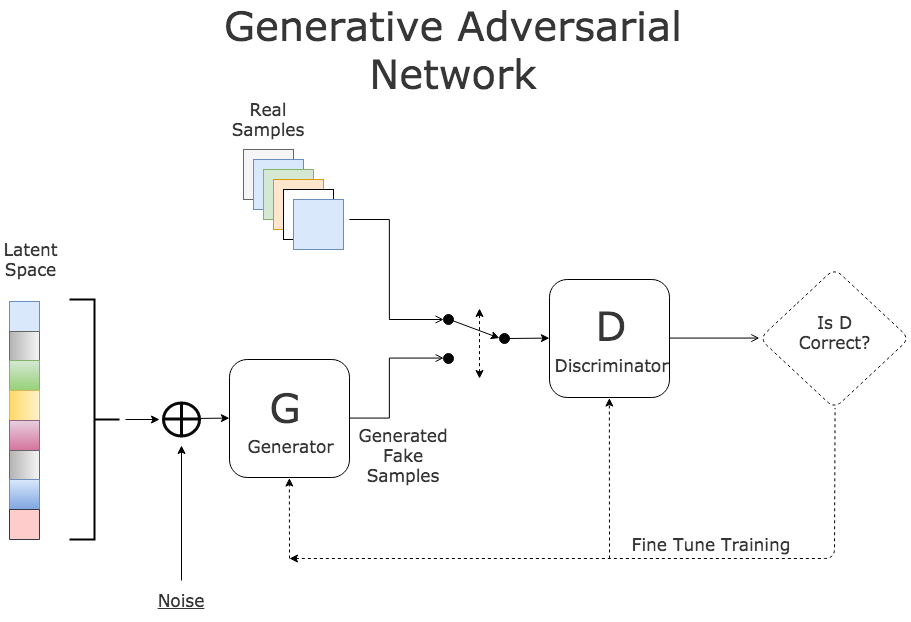
GANs are created through the usage of two different neural networks: a generative network and a discriminative network. The generative network trains on real-life input data to be able to develop synthetic images or other forms of data. The discriminative network is trained so that it can learn to discriminate between “real” and “fake” images. GANs are powerful because it connects these two different networks together.
A group of researchers from the Free University of Berlin have worked on a project called RenderGAN, which works to create labeled data from unlabeled data. For some background, unlabeled data signifies data, like images or text, without any sort of label or description about how the data is classified. Labeled data are the images or text with some sort of classification; for example, if the training data were about recognizing people, the labels would be “person” or “not a person”. This group trained their generative network with real data and started to create synthetic images while “[ensuring] that the resulting image still represents the given set of labels”[1]. Once this synthetic dataset was created, the group utilized it successfully in training another model that could predict the labels of real data. They applied their RenderGANs to the tracking of the identification of bees by binary code images, and it resulted in a 96% accuracy in tracking and identifying the bees. This high accuracy illustrates the ability to use synthetic data to create reliable models that work in the real world. Thus, the group was able to create very realistic synthetic data that successfully allowed the creation of an accurate model. The implications of these results are incredibly powerful; synthetic data can be used to train models to work on real-life data.
These researchers have illustrated the power of using synthetic data, but many people have concerns and qualms about using “fake” data. Although the data is not real, it is created through the GANs model, which produces images that are highly mathematically related to real world images. Thus, when using this data in other models, the results are very similar and have high success. However, a strict protocol in creating synthetic data is necessary to make sure that the data is not biased and inherently flawed. If researchers begin to use synthetically created datasets, there needs to be a strict rule about companies or people generating these datasets properly. GANs needed to be created properly and unbiased so that improper trends do not show up in datasets, which could severely impact others’ research. Furthermore, scientists that generate these datasets should also be transparent in their data creation; they should denote that data has been artificially generated. The ability to create and use synthetic data in research creates so much more potential in developing powerful and important models, but it requires a strict protocol so that corrupted data does not arise. In this big data revolution, the ability to generate more data is incredibly powerful. The ability to create larger datasets from a smaller set of data allows research to be conducted in many different areas where data previously did not exist. For example, new models can be developed on synthetic data for uncommon diseases or treatments. However, this also increases the opportunity for data corruption, so proper protocol needs to be developed to handle synthetic data. Sources: [1] Sixt L., Wild B., Landgraf T. “RenderGAN: Generating Realistic Labeled Data.” ICLR. 2017; 1-15.
0 Comments
Leave a Reply. |