|
Written by Holly Zheng, '22 Edited by Shailen Sampath, '20 If you read to Alexa the headline “China proposes removal of two-term limit, potentially paving way for Xi to remain president” in a standard American accent, Alexa will mostly understand your sentence with few mistranscriptions of words. If you read the same headline to her in a non-native English accent, however, she will think that you said: “China proposes removal of two time limit for ten shirley pain way folks eight remind president.” [1] The above result is from experiments conducted by researchers who teamed up with journalists of The Washington Post last summer. Their article revealed similar issues in recognizing non-American accents in many assistance devices besides Alexa, as shown by the chart. [1] 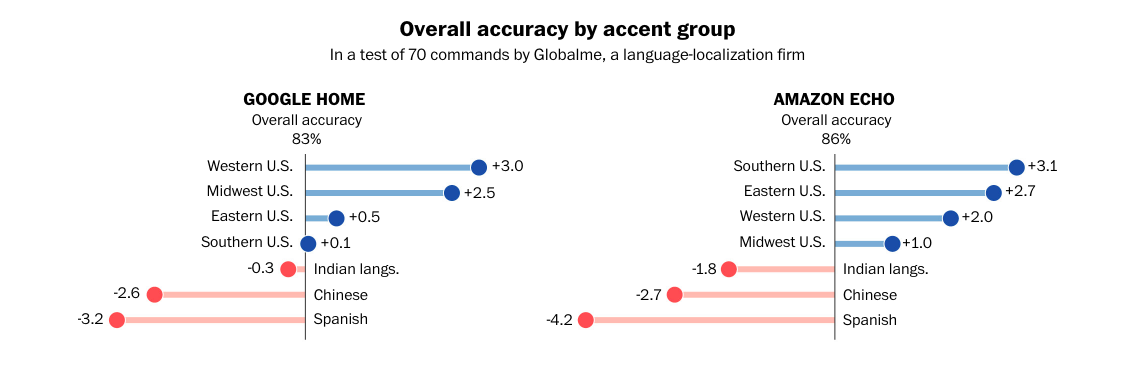 The “accent gap” of these otherwise highly intelligent machines is only one example of the “algorithmic bias.” This bias is caused by insufficient data from certain groups of device users or research targets. With not enough input from certain groups, the characteristics of these groups tend to not be represented in the final outcome of the data analysis -- a voice-recognition device, for example. Algorithmic bias manifests one of the alarming side effects of our big-data-centered world. With the ongoing fervor of machine learning spreading across diverse industries, the disparity between types of datasets in artificial intelligence research has surfaced.
A more recent article in Scientific American explores the need for diverse data in another field: genomic research. In the early days of genomic research, most of the funding went to institutions in mostly white countries, so underrepresentation of genomic data from ethnic minorities has long existed in the database for gene sequencing and disease research. Early studies on gene variation also only focused on small groups of DNA differences and ignored larger variations that were more difficult to access. [2] On a brighter side, progress aiming to close the gap in algorithmic bias has been increasing. In terms of the accent gap, many AI companies are taking the lead in improving voice recognition in intelligent devices. Speechmatics, a voice recognition company in Cambridge, UK, launched their “Global English” language pack in July, 2018, a comprehensive “package” for English. This package supports speech-to-text transcription in “all major English accents.” The research scientists and engineers also hope that as a device reaches more users, it will also become better at recognizing a wider variety of accents due to this rich data. [3] In order to achieve greater genomic diversity in gene research, many countries in Asia launched projects to collect genomic information from their diverse ethnic population. For example, a genome project in Korea found a population-specific variant in a gene that regulates how some medications are metabolized by the body, which is essential information for predicting a patient’s response to particular therapies. [2] One of the key areas that future efforts in gene data diversity should focus on, noted by the Scientific American article, is the field of rare diseases. Current treatment of many rare diseases are more effective on Caucasian population due to the lack of other gene types in disease research. [2] At the Datathon held by Brown Data Science Initiative this past February, Meredith Broussard, one of the guest speakers and an assistant professor of journalism at New York University, cautioned the audience against “technochauvinism,” the idea that technology is always superior than human beings. Sometimes, mathematical algorithms overwhelmingly outmatch human beings; other times, human judgement is indispensable. [4] Algorithms do exactly what scientists and engineers tell them to do, so if these algorithms are trained on databases that lack diversity, their ability often cannot extend to properly serve a more comprehensive population, no matter how carefully designed they are. As big data becomes more and more crucial in detecting patterns in the society, a well-represented population within the dataset is equally necessary. References: [1] Harwell, Drew, “The Accent Gap,” The Washington Post, July 19, 2018 https://www.washingtonpost.com/graphics/2018/business/alexa-does-not-understand-your-accent/?noredirect=on&utm_term=.6614e8944d22 [2] Korlach, Jonas, “We Need More Diversity in Genomic Databases,” Scientific American, March, 2019 https://www.scientificamerican.com/article/we-need-more-diversity-in-genomic-databases/ [3] Wiggers, Kyle, “These companies are shrinking the voice recognition ‘accent gap’,” Venture Beat, August 11, 2018 https://venturebeat.com/2018/08/11/using-ai-and-big-data-to-address-the-accent-gap-in-voice-recognition-systems/ [4] Rosenfield, Maia, “University event highlights complexities of data power,” Brown Daily Herald, February 21, 2019 http://www.browndailyherald.com/2019/02/21/data-can-influence-inequalities-panelists-say/?fbclid=IwAR11bFBKqH9ejRmYTm2_KGF64i381s2-udFWAgBpvJUb-aebs5AxHanxssg
0 Comments
Leave a Reply. |
